
Das Bestimmtheitsmaß der linearen Regression
Johannes Lüken / Dr. Heiko Schimmelpfennig
Von der Vielzahl an Gütemaßen ist das Bestimmtheitsmaß oder R² das bekannteste. Es gibt an, wie gut die durch ein Regressionsmodell vorhergesagten Werte mit den tatsächlichen Beobachtungen übereinstimmen.
Interpretation des R² in der linearen Regression
Formal ist das Bestimmtheitsmaß der Anteil der Varianz der abhängigen Variable, der durch die unabhängige(n) Variable(n) erklärt wird. Es kann insofern Werte zwischen 0 und 1 annehmen.
Abbildung 1 zeigt verschiedene Konstellationen der Beobachtungen einer unabhängigen Variable X und einer abhängigen Variable Y. Die lineare Regressionsanalyse bestimmt in diesem einfachen Fall mit den Regressionskoeffizienten den Achsenabschnitt und die Steigung einer Geraden, die möglichst gut alle Beobachtungen widerspiegelt. Wie gut dies gelingt, beschreibt das R². Ist R² = 1, so liegen alle Beobachtungen genau auf der Regressionsgeraden. Zwischen X und Y besteht dann ein perfekter linearer Zusammenhang. Je kleiner R² ist, desto geringer ist der lineare Zusammenhang. Ein R² = 0 bedeutet, dass zwischen X und Y kein linearer Zusammenhang vorliegt. Die Regressionsgerade ist eine horizontale Linie, die die Y-Achse in Höhe des Mittelwertes der Beobachtungen der abhängigen Variable schneidet. Aus R² ≈ 0 lässt sich jedoch nicht zwangsläufig folgern, dass gar kein Zusammenhang besteht. Er kann zum Beispiel quadratisch sein.
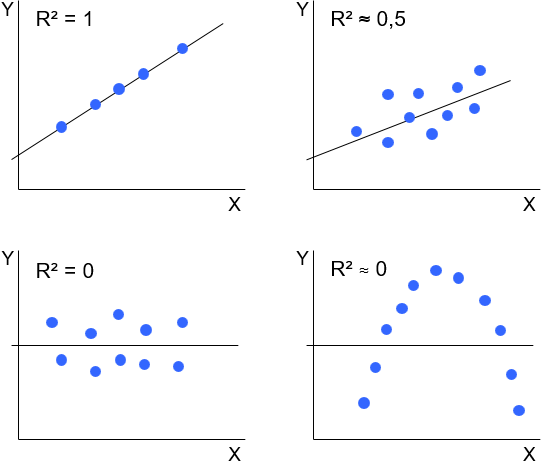
Abbildung 1: Beispiele geschätzter Regressionsgeraden
Beurteilung der Höhe des Bestimmtheitsmaßes
Grundsätzliche Empfehlungen, wie hoch das Bestimmntheitsmaß mindestens sein sollte, lassen sich nicht geben. Das R² hängt von der Höhe der Varianz ab, die überhaupt erklärbar, das heißt nicht durch den Zufall bedingt ist, und damit von der untersuchten Fragestellung.

Zudem tendiert das Bestimmtheitsmaß dazu, mit größerem Stichprobenumfang zu sinken. Dies lässt sich anhand des beispielhaften Streudiagramms in Abbildung 2 veranschaulichen. Gleichgültig ob (a) nur die drei roten oder (b) alle neun roten und blauen Beobachtungen zur Schätzung der Regressionskoeffizenten herangezogen werden, ergibt sich dieselbe dargestellte Regressionsfunktion. In (a) ist R² = 0,79, in (b) dagegen ist R² = 0,56. Je größer der Stichprobenumfang, desto eher gibt es zu demselben Wert der unabhängigen Variable bzw. derselben Kombination von Werten der unabhängigen Variablen unterschiedliche Werte der abhängigen Variable, so dass sich das R² verringert.
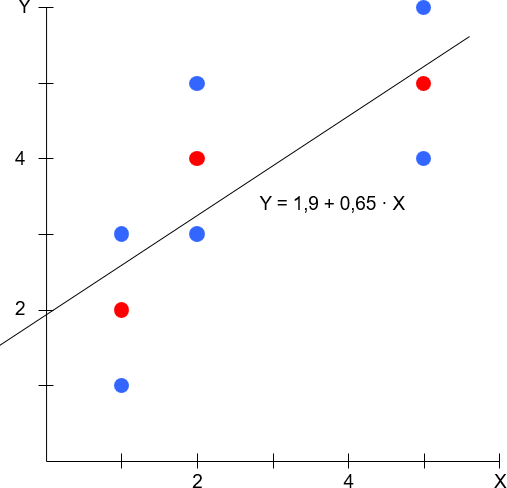
Abbildung 2: Stichprobenumfang und R²
Nichtsdestoweniger machen Autoren aus der Marketingforschung Angaben zu Grenzwerten. Für Strukturgleichungsmodelle nennen Homburg/Baumgartner (1995) 0,4 oder Hermann et al. (2006) 0,3, wenn das Ziel die möglichst gute Erklärung der abhängigen Variable ist.
Aber selbst Regressionsanalysen mit geringem R² können wertvolle Infomationen liefern. Der Einfluss einzelner unabhängiger Variablen kann statistisch signifikant sein, das heißt es werden Variablen identifiziert, mit denen die abhängige Variable verändert werden kann.
Relative Wichtigkeit einzelner Variable
Die Höhe der geschätzten Regressionskoeffizienten hängt auch vom Skalenniveau der Variablen ab. Der standardisierte Regressionskoeffizient β dagegen gibt unbeeinflusst vom Skalenniveau die Stärke des linearen Zusammenhangs zwischen einer unabhängigen und der abhängigen Variable an. Im Fall einer einfachen Regression entspricht er dem Korrelationskoeffizienten r. Dann ist das Bestimmtheitsmaß R² = β · r = r². Bei mehreren unabhängigen Variablen Xi ist R² = Σ(βi · ri). Demnach ist der Beitrag einer Variablen Xi zum R² gleich βi · ri und damit in Treiberanalysen ein Maß für die relative Wichtigkeit einer unabhängigen Variable für die abhängige Variable.
Beitrag aus planung&analyse 19/3 in der Rubrik „Statistik kompakt“
Autoreninformation
Johannes Lüken war bis 2021 Leiter des Bereichs Multivariate Analysen bei IfaD.
Prof. Dr. Heiko Schimmelpfennig ist Projektleiter im Bereich Data Science bei IfaD sowie seit Oktober 2021 als Professor für Forschungsmethoden an der BSP Business & Law School Hamburg tätig. Zuvor war er sieben Jahre Professor für Betriebswirtschaft und Studiengangsleiter an der University of Applied Sciences Europe. Er ist bei IfaD schwerpunktmäßig für die Beratung, Anwendung und Schulung von Multivariaten Verfahren verantwortlich und vertritt in der Lehre das Gebiet der Quantitativen Methoden der Wirtschaftswissenschaft.
Literatur
Hermann, A.; Huber, F.; Kressmann, F.: Varianz- und kovarianzbasierte Strukturgleichungsmodelle. In: zfbf, Nr. 1/2006, S. 34-66.
Homburg, C.; Baumgartner, H.: Beurteilung von Kausalmodellen. In: Marketing ZFP, Nr. 3/1995, S. 162-176.
<
Share



